
Tämä on toinen osa Microsoft Fabric -aiheisten kirjoitusten sarjassa. Ensimmäisessä osassa tarkastelimme Fabricia yleisellä tasolla ja pohdimme, mitä sen saapuminen tarkoittaa organisaatioille, jotka käyttävät nykyisin Azure Synapse Analyticsia tai muita Azuren datatuotteita. Samassa kirjoituksessa kävimme myös läpi kaksi yleistä käyttötapausta, kuinka Fabric edesauttaa niiden toteuttamisessa, sekä Fabricin lisensointi- ja kustannusrakennetta.
Tämä kirjoitus on luonteeltaan jonkin verran teknisempi. Tässä käydään läpi Fabricin tärkeimpiä eroja muihin Azuren datatuotteisiin ja erityisesti Azure Synapse Analyticsiin. Aluksi käsittelemme eroja Synapse Analyticsiin yleisellä tasolla ja sen jälkeen pureudumme tarkemmin jokaiseen Fabricin eri osa-alueeseen.
Erot Synapse Analyticsiin yleisesti
Näin Azure-käyttäjän näkökulmasta isoin ero Synapsen ja Fabricin välillä on se, että Fabric ei välttämättä vaadi lainkaan Azure-tiliä. Fabricilla on vahva kytkös Power BI -tuotteeseen ja sen käyttö onnistuu Power BI -lisensseilläkin. Lisensoinnista ja kustannuksista kerrottiin tarkemmin tämän kirjoitusten sarjan ensimmäisessä osassa.
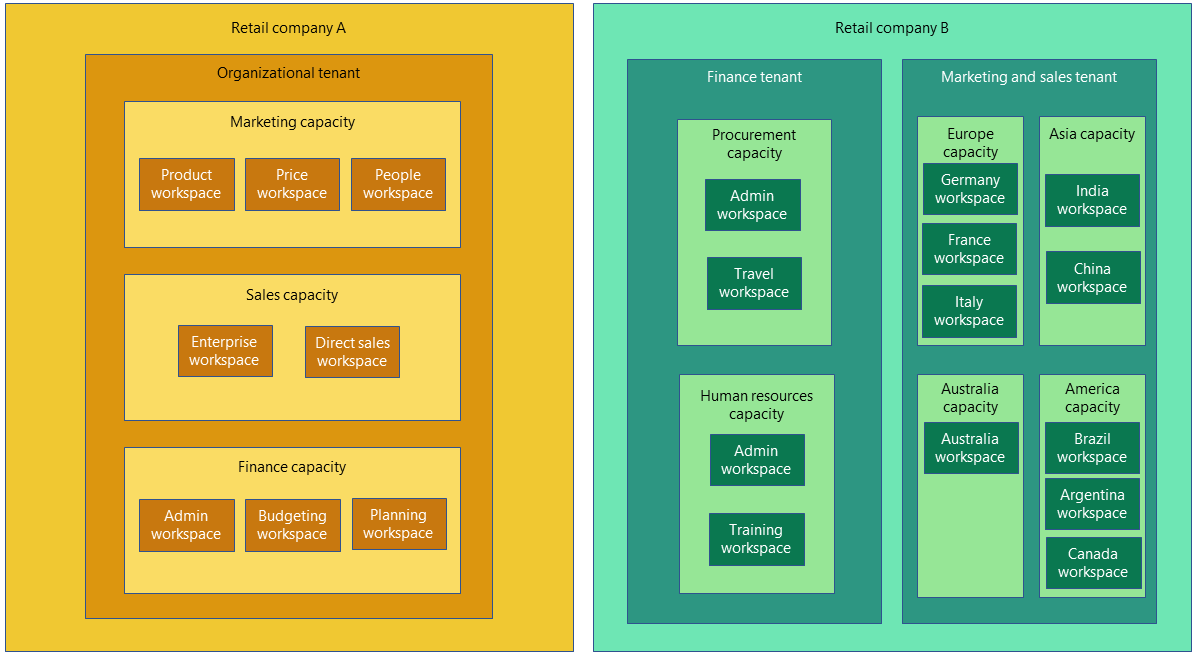
Fabric koostuu ylätasolla Tenantista, joka vastaa yleensä organisaatiota ja joka on sidottu Azure Active Directoryyn. Sen alle voidaan luoda yksi tai useampia Workspaceja, jotka voivat vastata esimerkiksi organisaation osastoja (oma Workspace myynnille, tuotekehitykselle, jne.). Tarvittaessa eri Workspacet voidaan vielä sijoittaa eri Capacityjen alle, jolloin voidaan ostaa eri määrä kapasiteettia kunkin Workspacen tarpeisiin. Tietovarastointia varten jokainen Workspace sisältää yhden tai useamman Lakehousen sekä yhden tai useamman Warehousen. Fabricin sisältämästä data lakesta ja lakehouse-käsitteestä kerron tarkemmin seuraavassa luvussa.
Azure Synapse Analytics oli ja on edelleen sateenvarjo, jonka alle Microsoft ihan onnistuneesti kokosi aiemmin erillisinä eläviä tuotteita. Fabric sisältää jopa vielä enemmän erilaisia tuotteita, minkä vuoksi ainakin tässä vaiheessa Fabricin käyttöliittymä voi vaikuttaa hieman sekavalta. Vasemman laidan ikonirivistö muuttuu sen mukaan, minkä osa-alueen (Data Engineering, Power BI, Data Warehouse, jne.) valitsee ”aktiiviseksi”. Toisaalta taas minkä tahansa osa-alueen asioihin, kuten vaikka Data Engineeringin notebookkeihin, pääsee käsiksi koska vain selaamalla Workspacen sisältöä.
Iso ero Synapseen verrattuna, ja samalla yksi Fabricin myyntivalteista on se, että se sisältää aina data laken valmiina, nimeltään OneLake. OneLake syntyy per Tenant. OneLaken sisältöä voi myös tarkastella työpöytäsovelluksella. OneLake integroituu osaksi kaikkia Fabricin osa-alueita, on se sitten Spark-notebookkeja, Data Factory -pipelineja, Power BI -raportteja, tai mitä vain. OneLake ei tarvitse mitään managerointia.
Ennen pitkää kaikille Fabricin osa-alueille tulee myös Git-integraatio sekä CI/CD-mahdollisuus, jotka mahdollistavat kehittäjille hyvin tutut työnkulut liittyen versionhallintaan sekä sovellusten julkaisuun eri ympäristöihin (eli esimerkiksi kehityksestä testiin ja edelleen tuotantoon). Tällä hetkellä sekä Git- että CI/CD-tuki ovat erittäin rajattuja. Power BI -raporttien teossa voi lisäksi hyödyntää uutta versionhallintaystävällistä tallennusmuotoa, joka on tekstimuotoista. Tällöin raportteja on mahdollista käsitellä versionhallinnassa samalla tavalla kuin mitä tahansa ohjelmakoodia, jolloin mm. muutosten seuranta ja yhteistyö kehittäjien välillä on helpompaa.
Käyttöoikeuksien hallinta on Fabricin kanssa erityisen helppoa, koska eri osa-alueet eivät ole enää erillisiä tuotteita vaan Fabricin kiinteitä osia. Myös dataan liitetty metadata, kuten merkintä sensitiivisestä tiedosta, on kaikkien eri osa-alueiden saatavilla.
OneLake
Fabricissa on oikeastaan kaksi erilaista ”lake”-käsitettä, OneLake ja Lakehouse, jotka liittyvät toisiinsa. OneLake on tenant-kohtainen tietovarasto, joka pitää sisällään kaiken Fabriciin säilötyn datan tenant-kohtaisesti valitulla Azure-alueella eli regioonassa. OneLake luodaan aina automaattisesti, eikä siitä tarvitse sen enempiä välittää.
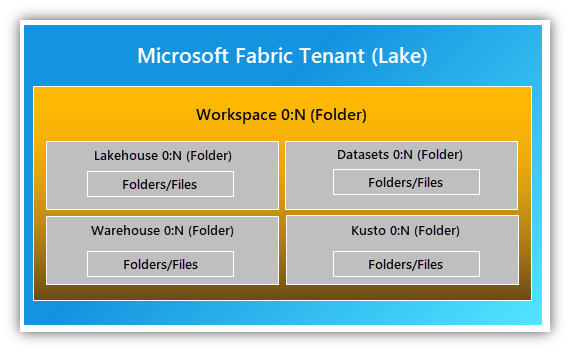
Lakehousen voi pohjimmiltaan ajatella olevan aivan kuten ADLS Gen 2 -pohjainen data lake. Nimitys ”lake house” tulee siitä, että siinä yhdistetään data laken periaatteessa loputon rakenteisen ja ei-rakenteisen tietovaraston tallennustila, sekä warehousen SQL-pohjaiset kyselyominaisuudet ja taulupohjainen näkökulma dataan. Lakehouseja voi Workspacen sisälle luoda niin monta kuin haluaa. Jos se on tarpeen, niin periaatteessa vaikka jokainen kehittäjäkin voi kehitysvaiheessa luoda oman Lakehousensa. Joka tapauksessa kaikkien eri Lakehousejen data on säilössä yhdessä ja samassa Tenant-kohtaisessa OneLakessa.
Iso uusi juttu Fabricin OneLakessa on se, että kaikki data on tallennettuna avoimessa delta parquet -muodossa. Parquet on toki tuttu tiedostomuoto jo pitkältä ajalta datan käsittelyssä, mutta delta on uudempi juttu. Delta lisää datan päälle tietokantatyyppisen ACID-kerroksen (atomicity, consistency, isolation, durability), joka mahdollistaa dataan kohdistuvat yhtäaikaiset luku- ja kirjoitusoperaatiot.
Koska tiedostomuotona on delta parquet -formaatti ja OneLake tarjoaa ulospäin samat rajapinnat kuin tavallinen ADLS Gen 2, pystyy OneLakeen säilöttyä dataa käyttämään myös esimerkiksi Azure Databricksistä käsin helposti. Tämä voi olla iso etu silloin, jos organisaatio on jo panostanut suuresti Azure Databricksiin datan käsittelyssä.
Tiedon hallintaan liittyen OneLake tukee ns. ”endorsement”-metadataa, jossa organisaation tietovarastoja voi merkitä ikään kuin suositelluiksi datalähteiksi. Isossa organisaatiossa tämä edesauttaa paljon datan löydettävyyttä. Löydettävyyteen liittyen myös Purview-tuki on mukana, joskaan se ei ole vielä täydellinen vaan kehittyy edelleen, kuten moni muukin asia Fabricissa.
Fabricissa on myös ns. “lineage”-näkymä ja siihen liittyvä ”impact analysis” -näkymä, jotka näyttävät visuaalisesti datan liikkumisen datan lähteistä niiden käyttökohteisiin ja erilaiset välissä olevat tietovarastot ja operaatiot. Näin pystyy tutkimaan, kuinka muutos jossain kohtaa prosessia vaikuttaa prosessin myöhempiin vaiheisiin.
Fabricin OneLake tukee myös ns. oikopolkujen tekoa olemassa oleviin tietovarastoihin. Tällöin niiden sisältö näkyy OneLakessa aivan kuin tieto olisi tallennettuna suoraan OneLakessa. Oikopolkuja voi Azuren lisäksi luoda myös AWS:n S3-tietovarastoon.
Data Engineering
Data Engineering tarkoittaa käytännössä notebookkeja, eli ihan samaa interaktiivista ohjelmointiympäristöä kuin mitä mm. Azure Databricks tarjoaa. Perusteiltaan Fabricin notebookit ovat aivan tuttuja, jos on käyttänyt juuri esimerkiksi Databricksiä (Azuressa tai muualla) tai Jupyter-notebookkeja missä vain.
Fabric tuo mukanaan muutamia tervetulleita uudistuksia ja parannuksia. Isoin muutos liittyy kuitenkin siihen, kuinka Fabricin tietovarasto eli Lakehouse yhdistyy saumattomasti notebook-kehitykseen. Koko Lakehouse on helposti nähtävissä notebookin yhteydessä omassa näkymässään ja siitä pystyy kopioimaan tiedoston polun suoraan notebookkiin. Enää ei tarvitse tehdä monimutkaisia toimenpiteitä muualla Azuressa olevien tietovarastojen näkyviin saamiseksi.
Notebookkeja voi myös kehittää ja ajaa VSCodella lisäosan asentamalla, jolloin notebookkia ajetaan Fabricin resursseilla, mutta suoritusta pystyy debuggaamaan omalla koneella. Tämä tosin onnistui lisäosan asentamalla jo Azure Databricksin notebookkien kanssa.
Kehityskokemusta parantaa tulossa oleva high concurrency -moodi, jossa pystytään ajamaan useita eri notebookkeja samoilla Spark-koneilla. Lisäksi taustalla olevat koneresurssit pidetään Microsoftin toimesta ”lämpiminä”, jolloin uuden session käynnistäminen kestää aiempaa huomattavasti vähemmän aikaa. Tästä lämpimänä pitämisestä ei edes seuraa mitään lisäkustannuksia, vaan kustannuksia tulee (eli Fabric-kapasiteettia käytetään) vain notebookkia ajaessa. Lisäksi pellin alla käytetään automaattisesti tiettyjä delta-taulujen optimointeja (V-order ja partition caching), joka parantaa suorituskykyä myös esimerkiksi lukiessa dataa lakehousesta Power BI -raportille.
CI/CD sekä Git-tuki notebookeille on Fabriciin tulossa myöhemmin.
Machine Learning/AI
ML/AI-työtehtävien suhteen Fabric vaikuttaa sisältävän samat asiat kuin nykyinen Azure Machine Learning -tuote. Experimenttien ajo eli mallien opettaminen löytyy Fabricista suoraan, aivan kuten mallien versiointi. Opetettuja malleja pystyy myös käyttämään suoraan esimerkiksi Fabricin Data Factory pipelineista.
Mukava uutuus on Data Wrangler -työkalu. Se on käytännössä interaktiivinen, visuaalinen tapa tutkia dataa (käytännössä Pandas-kirjastolla tehtyjä data frameja), tehdä siihen aggregointeja ja muita operaatioita käyttöliittymässä, jonka jälkeen operaatiot voi tuoda koodina notebookkiin.
Fabricista löytyy myös natiivi tuki R-kielelle, kun Azure Machine Learningissa R-koodia piti ajaa Python-koodin kautta.
Lisäksi Fabriciin on tulossa käyttöön Azure Cognitive Servicen tarjoamat valmiit tekoälymallit.
Data Factory
Data Factoryyn on käytön helpottamiseksi tehty joitain muutoksia. Vanhasta Data Factorystä tuttua publish-vaihetta ei enää ole ollenkaan. Myös monitoroinnin pitäisi nyt olla parempi. Iso etu myös tällä puolella on Lakehousen ja Data Warehousen saumaton integraatio osaksi Data Factoryä.
Data Factoryyn on tulossa joitain uusia integraatioita, mutta toisaalta vielä tässä vaiheessa kaikki vanhat tutut integraatiot eivät välttämättä ole tuettuja. Myös muita isoja puutteita on vielä:
- Self-hosted integration runtime puuttuu ja se on vasta suunnitteluasteella.
- Samoin Azure SSIS integration runtime, MVNet sekä Private End Point puuttuvat.
- CI/CD on vasta tulossa.
Real-Time Analytics
Reaaliaikaisen datan käsittely on oikeastaan kokonaisuus, jolle ei ole aivan suoraa vastinetta Azuressa entisestään. Se on ehkäpä yhdistelmä Azure Stream Analyticsia ja Data Factoryä. Nopean testailun perusteella homma vaikuttaa kyllä erittäin toimivalta: on todella helppoa luoda Fabricin sisälle ns. custom app, joka tarjoaa Azure Event Hub/AMQP -rajapinnat, joihin voi lähettää dataa. Datan saa sen jälkeen laitettua suoraan talteen Lakehouseen delta-tauluun tai KQL-tietokantaan. Tämän jälkeen se on käytettävissä helposti esimerkiksi Power BI -raportilla.
Data Warehouse
Fabricin Data Warehouse -puoli on mielenkiintoinen ensinnäkin siksi, että se on täysin SaaS-pohjainen, eikä se tällöin tarvitse minkäänlaista hallinnointia fyysisten resurssien suhteen. Toisekseen tietoa ei tallenneta enää Microsoftin suljetulla tiedostoformaatilla, kuten SQL Warehousessa, vaan avoimella delta-parquet-formaatilla. Warehousen data on myös suoraan nähtävissä Fabricin OneLakessa ja koska se on delta-parquet-muotoista, pystyy sitä hyödyntämään millä tahansa asiakasohjelmalla tai ohjelmallisesti. Myös erilaisten tietolähteiden yhdistäminen samaan Data Warehouseen on nyt todella helppoa, jos lähtödata on delta-parquet-muotoista. Tällöin dataa pystytään yleensä lukemaan suoraan lähteestä ilman että sitä tarvitsee kopioida OneLakeen.
Myös Data Warehouseen on tulossa Git ja CI/CD -tuet. CI/CD tulee mahdollistamaan esimerkiksi skeemojen vertailun eri ympäristöjen välillä tehtäessä versiopäivityksiä.
Power BI
En ole varsinaisesti Power BI -asiantuntija, joten en mene Power BI -puoleen kovin syvällisesti tässä yhteydessä. Yksi iso ja suorituskykyä tuova uudistus on kuitenkin Direct Lake -moodi, jossa Power BI -raportti on suoraan yhteydessä OneLakessa olevaan dataan.
Yhteenveto
Kuten totesimme jo Fabric-aiheisten blogikirjoitusten ensimmäisessä osassa, sisältää ensinäkemältä tutun oloinen Microsoft Fabric pellin alla lukuisia hyviä uudistuksia ja parannuksia. Uskoisin, että Fabric voi dataan liittyvissä kehityshankkeissa parhaassa tapauksessa sekä helpottaa kehittäjän elämää, parantaa sovelluksen laatua, että myös pienentää sovelluksen juoksevia kuluja sen käytön aikana (tai ainakin helpottaa kustannusten seurantaa). Varmistus näille lupauksille kuitenkin saadaan vasta sitten, kun käyttökokemuksia tuotteesta saadaan lisää.
Jos on juuri tällä hetkellä aikeissa aloittaa uutta datahanketta Azuressa, kannattaa vähintäänkin tarkistaa, mitä eri palasia hankkeesta pystyisi Microsoft Fabricilla tekemään.
Hyödyllisiä linkkejä: